Why we replaced Kafka transactions with an adapter pattern
8 min read
A few weeks into running the new platform under production-like load, reconciliation started getting stuck. The audit service would tally up the day’s messages for a tenant, find its count short by a handful, and refuse to close out the batch. We’d dig in, find that one of the upstream services had published a message to its downstream topic but not to the audit topic, patch it up by hand, and watch the same thing happen on a different tenant the next day.
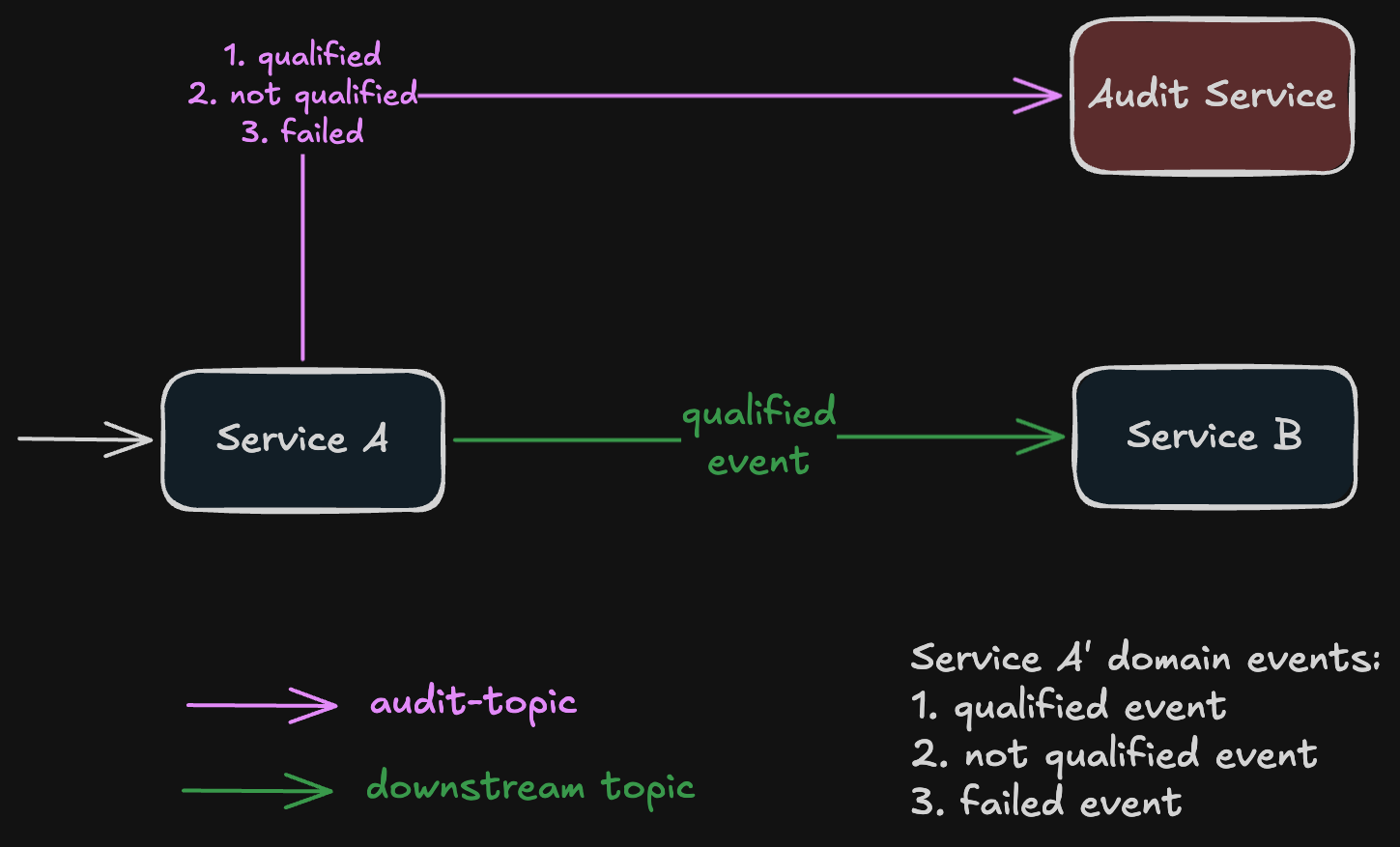
The platform is a multi-tenant compliance system we are rebuilding from scratch to handle up to 25 million messages per tenant. It runs around ten Java microservices on Kubernetes, all communicating over Kafka. One of them, call it Service A, had a job we didn’t think much about at first: publish each processed message to two Kafka topics. That dual publish is where things went wrong.
The setup
Service A produces three kinds of domain events. A qualified event means the message has passed all checks and the next service downstream should pick it up. A not-qualified event means the message was processed but didn’t meet the criteria. A failed event means something went wrong during processing.
Service B, the next service in the pipeline, only cares about qualified events. The audit service needs all three, so we can reconcile end-to-end counts and confirm every ingested message reached an end state. Reconciliation is non-negotiable in compliance work. If even one message is missing from the audit trail, we can’t say the day’s batch is fully processed.
So Service A was publishing qualified events to a downstream topic for Service B, and all three event types to a separate audit topic for the audit service. Two sends, two topics, one message. That was the source of the missing audit records.
Why two sends fails more often than you’d think
When the same producer publishes a message to two topics, those are two independent operations. The first can succeed and the second can fail. The application can crash between them. A broker can be down, or there can be a network blip during the second publish, leaving you with one topic that has the message and another that does not. The Kafka client we use (spring-kafka) retries internally, but after ten retries it gives up and propagates the failure.
We were running this pattern across fourteen services at an aggregate ingestion rate of around 300 messages per second, all hitting the same Kafka cluster. Failures were not rare. Mismatches between the downstream topic and the audit topic showed up often enough that reconciliation, which has to confirm an end state for every ingested message, would block on each tenant where one slipped through. Hunting down a single missing message is fine. Hunting them down every day at that volume is not.
Why Kafka transactions seemed like the answer
The textbook fix for atomic multi-write is two-phase commit, and Kafka has its own version. KIP-98 introduced transactional messaging and gives you exactly-once semantics across multiple topic-partition writes. The producer wraps the two sends in a transaction. Either both topics get the message or neither does. A transaction coordinator on the broker orchestrates the protocol with the partition leaders.
We implemented it, promoted it from staging to our performance environment, and let our automated baseline test run overnight. The test ingests 400k messages and is our daily check that we haven’t regressed throughput. The hard requirement is that the new platform be at least as fast as the existing one, which did around 250 messages per second on this metric.
The morning after the change, throughput on the main processing service had dropped to about 60 messages per second. Lag on its input topic climbed steadily through the test window. The service was spending most of its time inside the transaction protocol.
The overhead comes from the protocol itself. Each message produced inside a transaction triggers several extra round trips: register the partition with the transaction coordinator, the produce, then the prepare and commit phases at the end. We weren’t batching multiple messages into a single transaction. Each business message had its own transaction with at least five extra synchronous network calls on top of the produce.
We scrapped Kafka transactions after about two weeks. We never got to a thorough analysis of how transactional batching might have changed the picture, because the regression was too large to keep on the platform while we tuned it.
The approaches we ruled out
Putting all three event types on a single topic and letting Service B filter would have been a small code change. The problem is that Service A’s domain now leaks into Service B. Service B has to know what to discard, and every new event type Service A adds becomes a change in Service B too. Service B also burns CPU and memory consuming messages it is going to throw away, which makes its own throughput metric misleading. We rejected this for the domain-boundary reason more than the cost one.
A separate filter service between A and B moves the responsibility somewhere else without removing it. Another service to deploy, monitor, and scale. Moving the garbage to another room isn’t the same as taking it out.
A routing layer with rule-based forwarding (an event bus, broadly) is a new piece of infrastructure to provision, configure, and operate. Not worth it for what was essentially a publishing problem.
The adapter pattern
The pattern we landed on is short to describe. Service A publishes qualified events to the downstream topic where Service B consumes them. Service A also runs a second consumer, in a different consumer group, that listens to its own qualified topic and forwards each event to the audit topic. Not-qualified and failed events still get published directly to the audit topic by Service A, since no downstream service needs them.
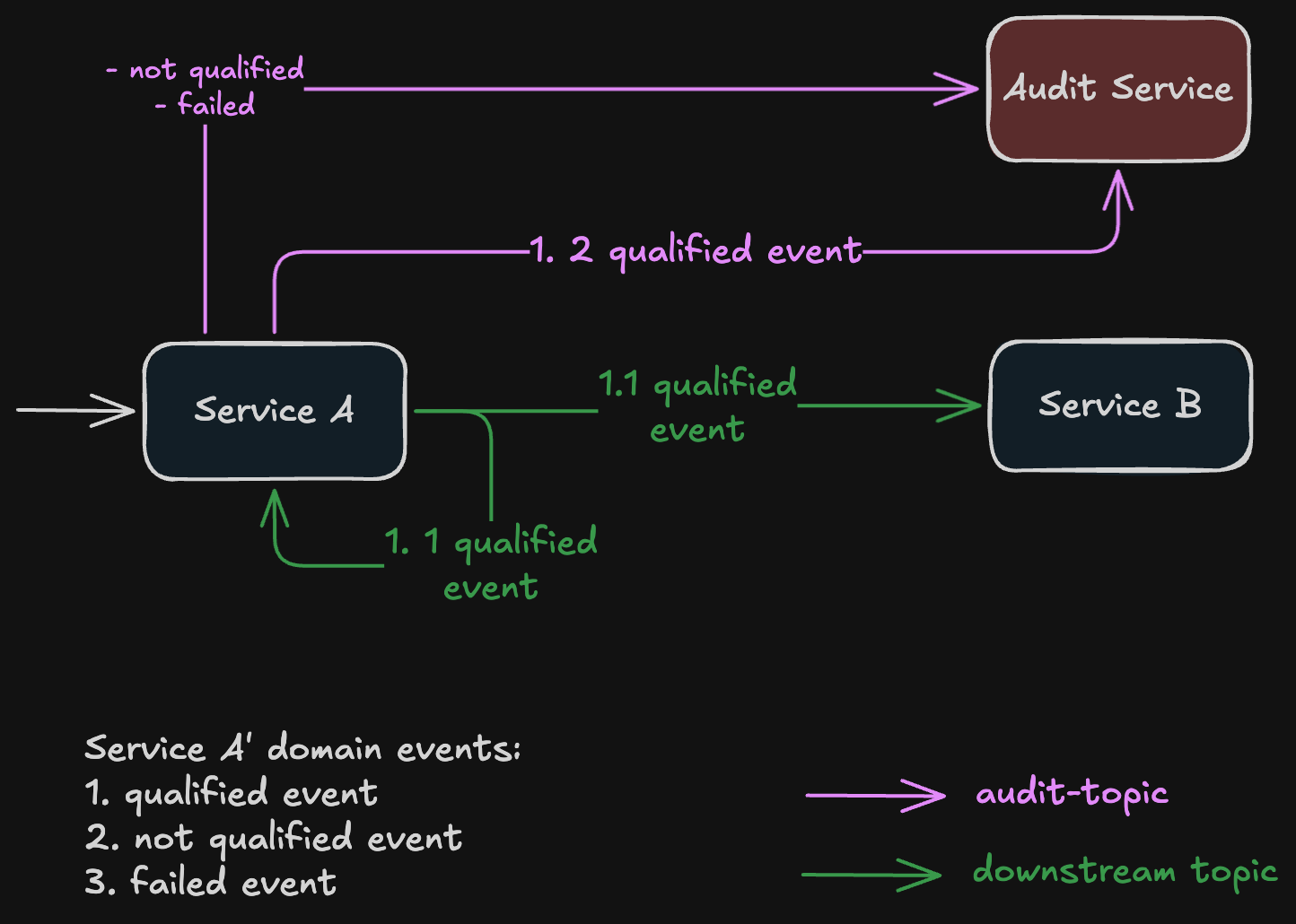
The key detail is the second consumer group. Kafka delivers each message in a topic to one consumer per consumer group. Service B is in one group; Service A’s adapter consumer is in another. Both groups see every qualified event at their own pace. The adapter consumer’s only job is to take the qualified event off the downstream topic and republish it to the audit topic.
This looks like it just moves the dual-publish problem one step over, but it doesn’t. Service A is now publishing to one topic at a time. There is no atomic two-topic write to fail half-way. The qualified event on the downstream topic is durable in Kafka, so the adapter consumer can always retry from where it left off if anything goes wrong. The audit publish from the adapter is a single send.
Failure scenarios
If Service A fails to publish to the downstream topic, neither Service B nor the audit service gets the message. There is no inconsistency, just a failure, which is what our 1% error budget is for. We alert if it crosses that across the daily corpus of 20 to 25 million messages.
If Service A publishes to the downstream topic successfully and Service B consumes it but the adapter consumer fails, the qualified event is still on the downstream topic. When the adapter consumer comes back up, it picks up where it stopped and the audit service eventually gets the message. The system is eventually consistent over that window.
If the adapter consumer succeeds but Service B fails, the same story applies in reverse. The audit service has the record. Service B catches up when it recovers, because the message is still durable in the topic.
In all three cases, we rely on Kafka’s at-least-once guarantee and the durability of the downstream topic. The adapter consumer is just another Kafka consumer, with the same recovery semantics as any other.
What changed in production
We deployed the adapter pattern across the services that publish to audit (around nine of them) about two months ago. Throughput on the daily baseline test went back to its pre-transactions level. We haven’t seen the audit-vs-downstream count mismatches that were getting us stuck on reconciliation. Memory on Service A didn’t need adjusting after adding the second consumer, though we probably had headroom there to start with.
The trade is explicit. We gave up exactly-once across two topics, which Kafka doesn’t give us for free without transactions. We got back our throughput and stopped seeing inconsistencies in practice.
Caveats
This works because eventual consistency between the downstream service and the audit service is acceptable for us. If the audit service and the downstream service must see the same message in the same logical step, this pattern doesn’t help.
It also assumes the downstream topic is durable enough to be your recovery point. If retention on that topic is short, you can lose messages the adapter consumer hadn’t gotten to yet. Our retention is longer than any realistic recovery window.
Monitoring still matters. The error budget catches publish failures, but a silently stuck adapter consumer would let audit lag grow without alerting until someone noticed reconciliation slipping. Lag alerts on the adapter consumer matter as much as the publish alerts on Service A.
Closing thought
Kafka transactions are the textbook answer for atomic multi-topic writes, and they cost real throughput when used at the granularity of a single business message. That cost can dwarf the cost of the inconsistencies they’re meant to prevent. Once we asked what consistency we actually needed instead of how to make two publishes atomic, the rest of the design fell out in an afternoon.